I have an application where I have two XEM7360’s connected to a PC and I’m reading them both out in parallel with a multithreaded C application. I am trying to track down a bug that causes the FPGAs to time out, but the problem is that I’m working remotely and sometimes when the FPGAs time out they can no longer be recognized again without a power cycle.
When I look in the device manager it says that the USB device crashed unexpectedly and is no longer recognizable.
So, is there any way to force a software reset or something similar on these ports to get them to be recognized again? I tried to Scan for USB devices in Frontpanel but that doesn’t do anything. Restarting works for one of the two devices, but not the second. A power cycle always works, but that requires me asking someone else to unplug them every time this bug happens.
Are you performing larger reads on a blockpipeout or a normal pipeout? Can you share any information regarding the errors you receive from your application?
More information about your setup could be helpful:
-Information about your host PC, make and model?
-Host operating system?
-FrontPanel SDK Version?
Unfortunately, there isn’t software reset functionality. You’ll need to manually power cycle it for the time being.
I am performing a 4 MB read on a block pipe out with block size 16384 B. I’m getting a Error Code of -1, which from the error code page is a non-descript lower level error.
I’m using a workstation with the following parameters. I’m not sure which version of the SDK I’m using … how do I find that out? I downloaded it a few months ago.
EDIT. Looks like I’m using 5.2.2. At least according to my FrontPanel Help window.
EDIT: I updated to 5.2.4. It didn’t fix the issue.
You seem to be experiencing a number of levels of corruption or issues with this set up. In cases like this, it’s important to simplify as much as you can to determine the root cause, then build things back up.
Multithreaded applications can add a lot of complexity that is not easy to trace. Our suggestion is to reduce the problem to a bare minimum, testable, repeatable situation with a single board, single-thread, and very basic structure. Then increase the complexity until you find the fault.
Yes, I’ve done that. I removed all multithreading, a single board, and very basic structure. It works for a bit, then I get a -1 code error on my readfromblockpipeout function once, and then it repeatedly fails.
There is very little information on what a -1 error even means… is there any more information besides a non-descript low level operating system error?
So I’m readout out 4 MB chunks in blocks of 16kb. Due to my design, there can be a substantial delay between blocks being ready. So while there may be a few 16kb blocks available, there might be several hundreds of ms before the rest of the 4 MB chunk is ready. Ep_ready is only asserted when a block is ready, but that doesn’t seem to matter. What causes the error is the delay between the C function call and the total completion. The result is weird. The FPGA serial number gets corrupted into weird ASCII symbols, I get a -1 error code, I have to power cycle the FPGAs, and sometimes restart the computer.
What seems to solve the issue is to route ep_ready to a wire_out and monitor it. Then I break up the large 4 MB readfromblockpipeout() call into 256 smaller ones, of block size 16 kb and total size 16 kb. While the end result is still 4 MB, I only call the C function if the fifo has available data, so there is little delay between the C call and data being available.
This seems to work, but I have no idea why. There is no documentation stating that there should be little delay between blocks, and I don’t get a timeout error.
Anyways, a since removed post stated that there are known issues with large BTpipes, so I hope that this information helps track down the bug.
How long does your application take to generate the 4 MB required to complete.
Block Pipes are intended for transfers that are close to the limits of the achievable USB data rate but that still require some throttling due to limited buffer space. If this isn’t the case, then the preferred approach is to use wires or triggers. The reason for this is that you can use smaller, atomic transfers and still achieve your performance goals. This improves application and I/O system responsiveness.
We would suggest trying to build the application without block pipes and using simpler methods to check data availability. Alternatively, try using smaller transfers (say 256kB at a time).
Regarding your data corruption issue… is your pBuffer large enough to contain the full data? What you’re seeing smells like a data corruption issue on the software side – as if some data is overwriting the okCFrontPanel object itself.
There are no known issues with BTPipes. They have been used successfully in hundreds of applications.
How long does your application take to generate the 4 MB required to complete.
That depends on the settings of the experiment. Anywhere from 15 ms to 500 ms. This puts the bandwidth requirement in the range of 266 MB to 8 MB. The higher end is too fast for wires, so I’m using pipe outs.
Regarding your data corruption issue… is your pBuffer large enough to contain the full data? What you’re seeing smells like a data corruption issue on the software side – as if some data is overwriting the okCFrontPanel object itself.
Yes it is. I check for this, and if the above mentioned error occurs in my C program and I close C and then run Frontpanel, the same corruption shows up in the Frontpanel application under the FPGA information. I’m assuming that closing my application and then rerunning Frontpanel would create new okCFrontPanel objects?
Alternatively, try using smaller transfers (say 256kB at a time).
If you’re able to create a very short and simple test case (HDL + C++) that recreates this condition, please submit it to [email protected]. Ideally, you’d be able to make very minimal (if any) changes to our existing PipeTest.
I have not been able to do this yet, and am still getting my weird -1 error. However, I was digging through the FrontPanel HDL code and I noticed something peculiar.
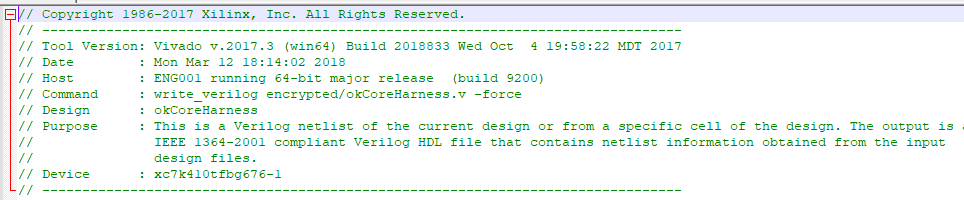
In all of the files included in the FrontPanel HDL XEM7360 the device is listed as an xc7k410tfbg676-1, however, I have a -3E speed grade. Would this matter?
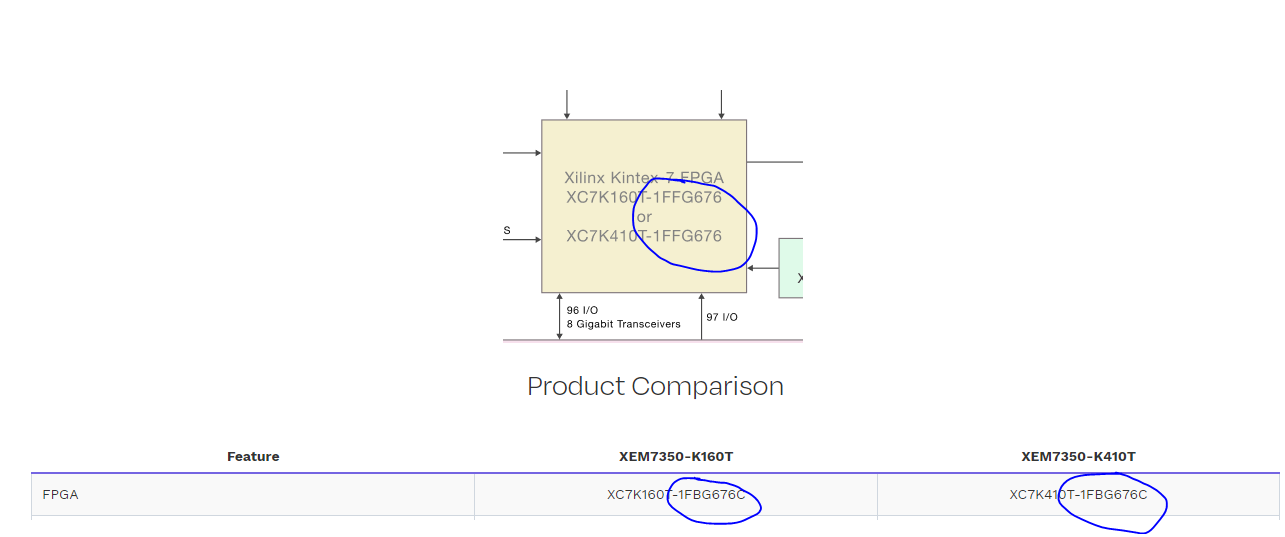
Also, according to the block diagram in the documentation, both of the XEM7360s come in the ffg676 package, but in the specifications table it says its the fbg676 package. EDIT: I just noticed that the specifications table on the XEM7360 page is for the XEM7350. At any rate, I imagine Vivado would throw an error if the code was built for the wrong device… but so far with my project set to be the ffg676 package… there are no errors thrown.
Could these subtle errors be causing issues?
EDIT:
Another piece of information is that if it is, in fact, in the FBG package as the Verilog files say, then that package will not operate at 800 MHz for the DDR3 MIG. In fact, the wizard won’t even let you input that value. So the 800 MHz value as listed on the ‘DDR3 MEmory Walkthrough’ section of the user guide wouldn’t work.
I am still wondering if the fact that the device listed in the encrypted OpalKelly files needs to exactly match the XEM7360’s device, because it currently does not (fbg676 instead of ffg676 and speed grade mismatch).
The package and speed grade details are important during place and route for the tools to determine proper timing of the result. They are not applicable to the synthesis step nor are they applicable to the source encryption step but the tools require this information to perform the source encryption which is why we are able to deliver one set of sources regardless of the package, density, and speed grade.
This mismatch is not pertinent to the issue you are having.